



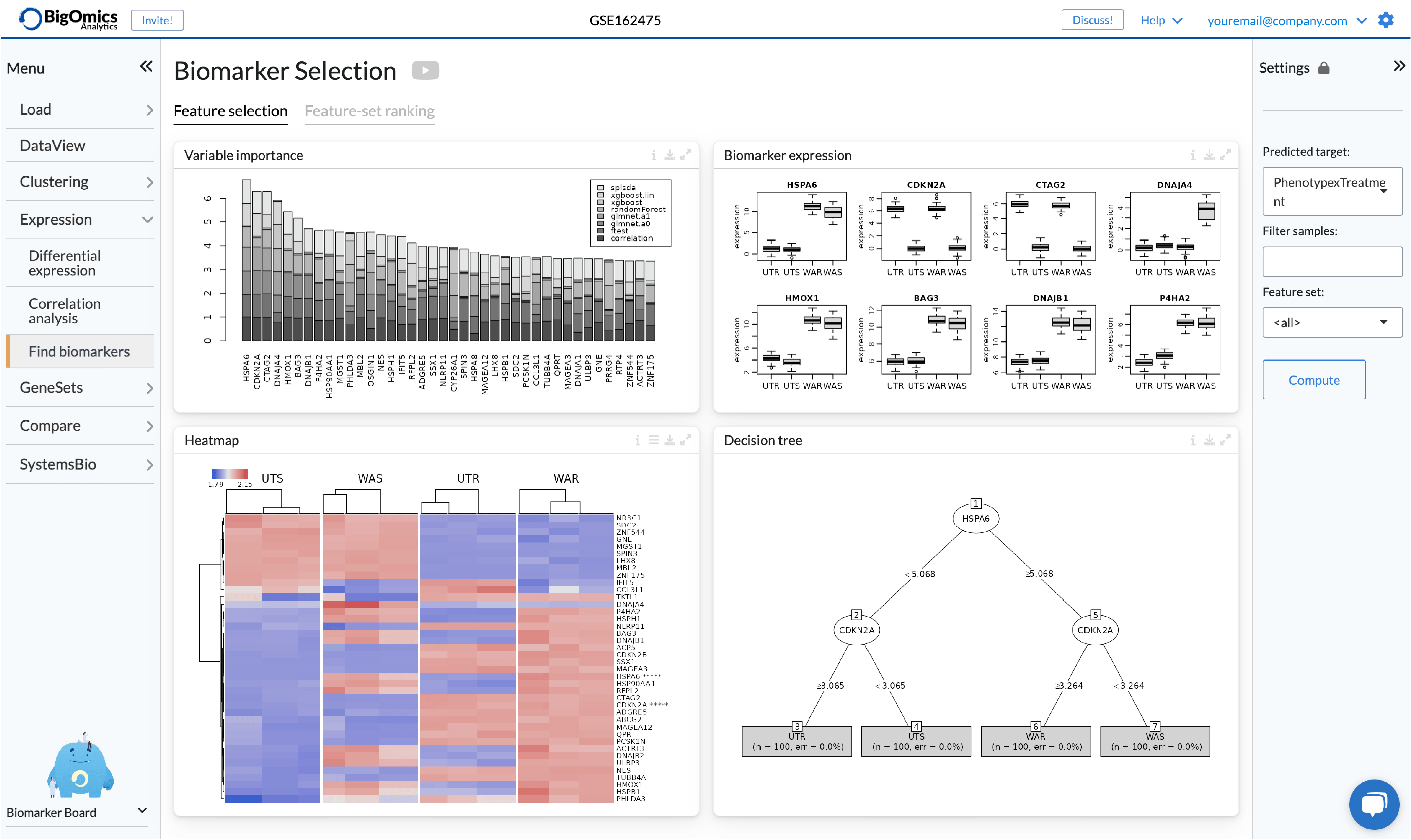
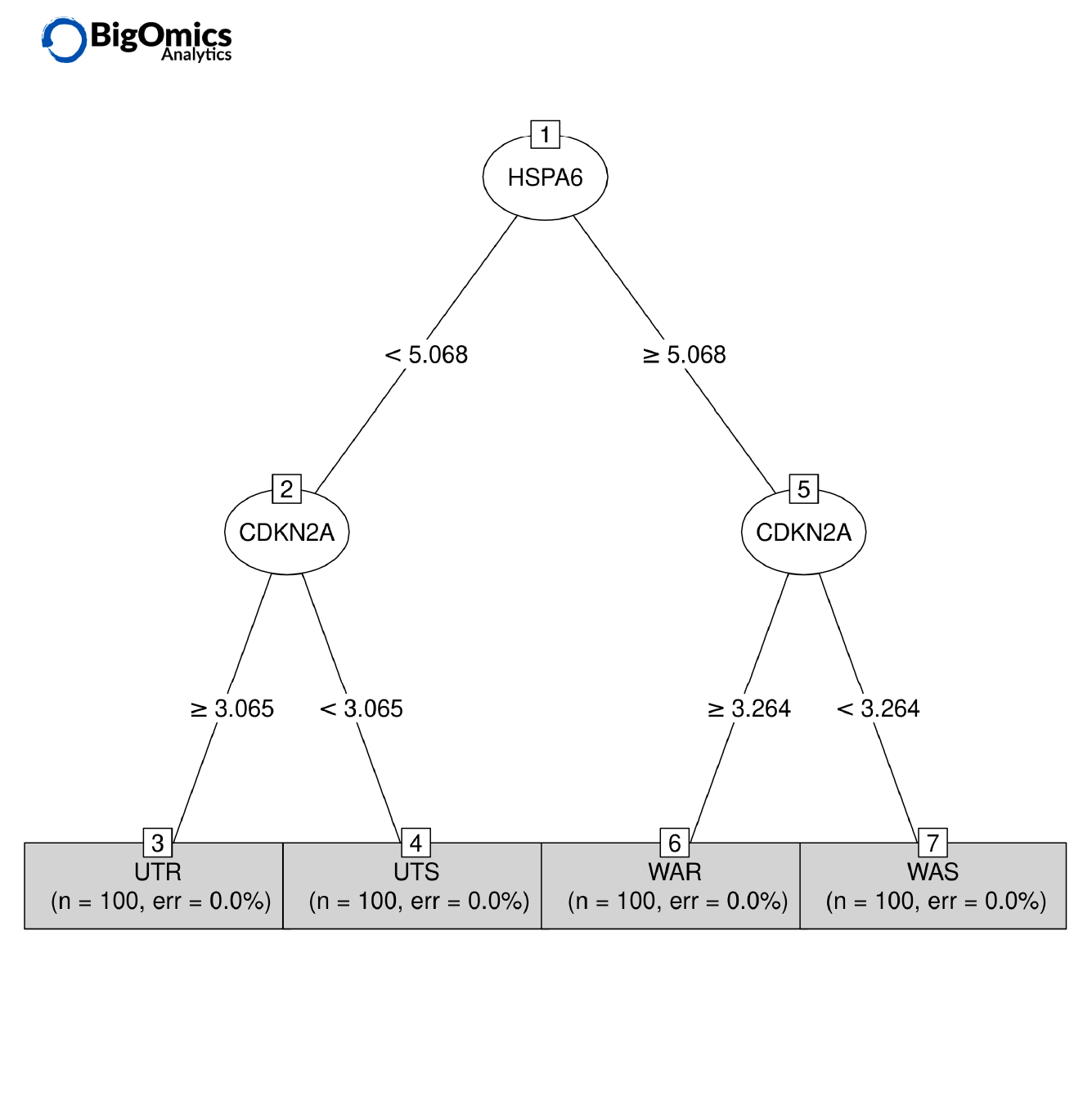
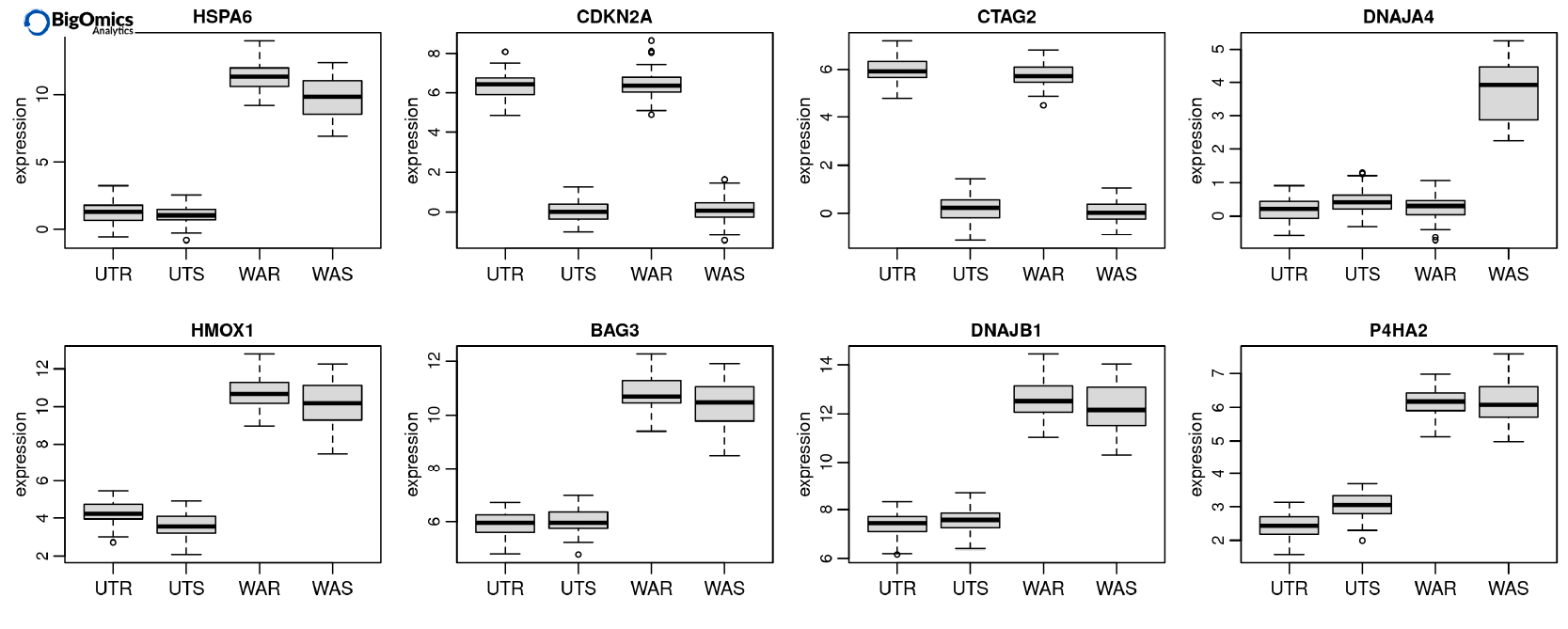


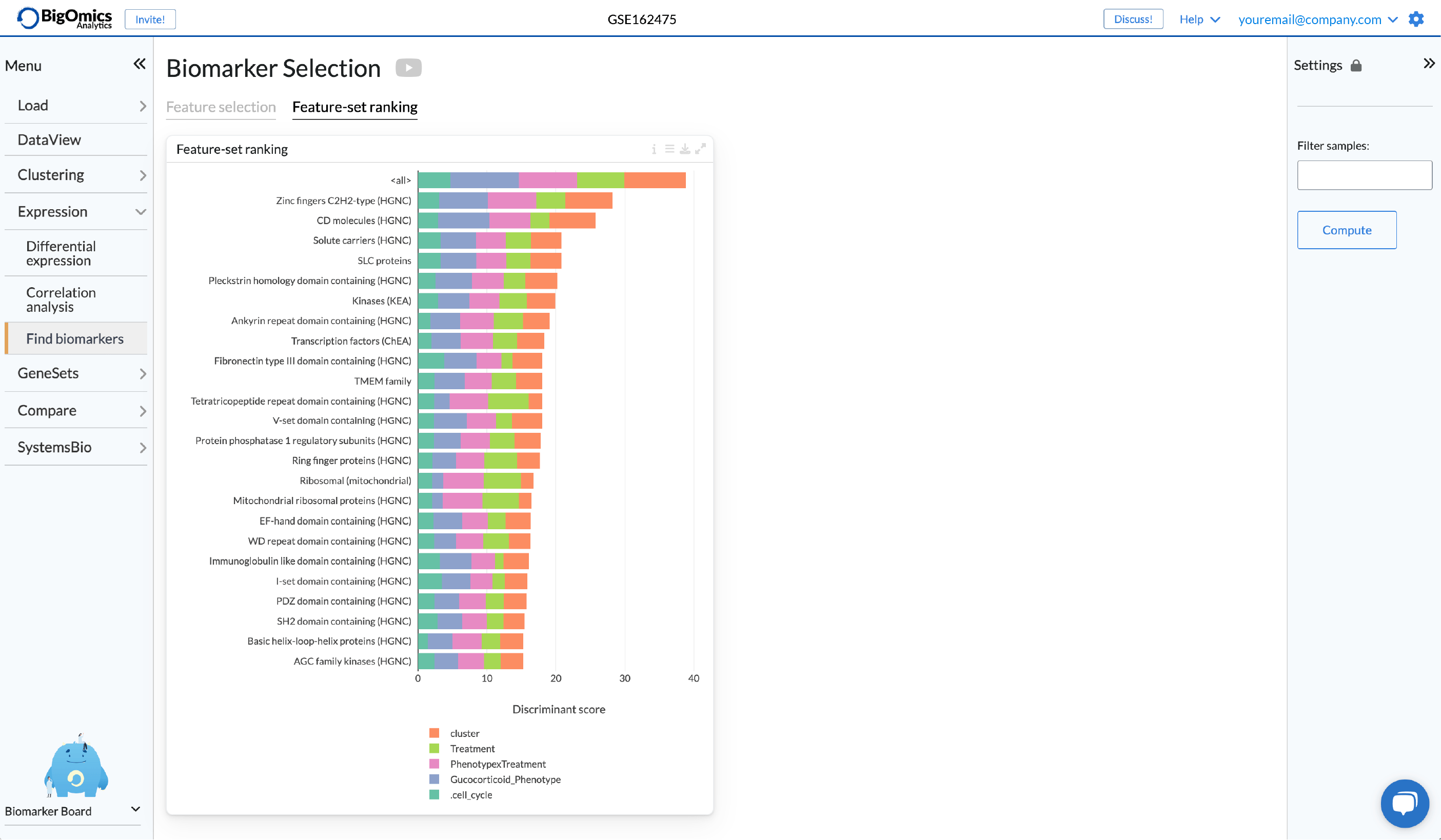


Axel Martinelli’s academic background is in molecular biology and parasitology. He earned a Ph.D. on the genetics of strain-specific immunity against malaria infections and a master’s degree in bioinformatics with specialization in the analysis of omics data. During his postdoctoral career, he worked on genomics and transcriptomics studies and is currently the head of biology at Bigomics Analytics.